Back in 2013, The Guardian proposed that our political speeches are declining in linguistic sophistication. Then, in 2015, Politico’s data analysts concluded that Donald Trump speaks at the level of a third-grader. Today, in 2016, the same man has been elected as our next President.
Are we increasingly favoring less sophisticated political speech? This question is at the heart of a fascinating project led by CDS’ very own Arthur Spirling, along with Kenneth Benoit (LSE) and Kevin Munger (NYU).
Like the case studies in The Guardian and Politico, the team defines linguistic sophistication as the ‘perceived readability’ of a text according to a particular measure. Today, the standard readability measure is the Flesch Reading Ease (FRE) test. Part of FRE’s process involves calculating the average sentence length of a passage and the average number of syllables per word. The full calculation is as follows:
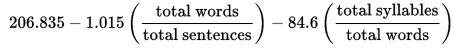
The higher the score, the more linguistically complex the passage is. For example, the approximate FRE score for Dr. Seuss’ The Cat in the Hat is 0.7, while George Washington holds a score of 19.3. In contrast, Donald Trump, when speaking in 2015, scored 0.9.
But although FRE is useful, it hits some stumbling blocks when applied to political texts. For example, FRE overlooks how colloquial diction changes over time. Although “forsooth the cordwainer was afeard” would score the same as “indeed the shoemaker was frightened” since they have the same number of words and syllables, the latter is clearly more ‘readable’ for today’s audience. FRE calculations also do not account for the persuasive power of rhetorical devices like repetition: repeated sentences simply score the same and do not affect the overall FRE score.
Benoit, Munger, and Spirling are hoping to overcome these challenges by developing a new measure that is not only tailored to handling political texts, but also tempered by human judgment.
To start, the trio collected the word frequencies of an astounding total of 760,653,149,209 words from the Google Books corpus, and then sorted their frequencies by decades. This data allows their model to measure whether specific words are in or out of fashion based on how often it was used in the English language overall during the time period that the text was written in.
The team also crowd-sourced some comparison data. After extracting one or two sentence snippets from several state of the union speeches, they asked users to compare two snippets at a time and decide which one was easier to read. Recording this human judgment data helps their model capture the implicit effects of rhetorical devices like repetition.
After fine-tuning their model, the trio hopes to analyze political speeches in other contexts, from congressional floor speeches to debates. Their model will also be released as a part of the quanteda R package so that other researchers can apply their methodology to their own research projects.
Benoit, Munger, and Spirling’s project represents some of the values that CDS holds most dear: innovative approaches, interdisciplinary research, and a collaborative spirit. Their project also marks an incredibly exciting time for researchers interested in analyzing text-as-data.
by Cherrie Kwok