Combating reproducibility issues with standardized procedures
In this era of strange, burgeoning technologies, it is not uncommon to hear a wistful, “Remember the old days? When life was simpler?” Well, until recently, music information retrieval (MIR) was a simpler world too. As MIR tasks and methods have become increasingly complex, modern researchers have a responsibility to adequately document their work.
In their recent publication, Brian McFee, CDS Assistant Professor of Music Technology and Data Science, Jong Wook Kim, PhD student in Music Informatics at NYU, Mark Cartwright, Research Assistant Professor at NYU’s Music and Audio Research Laboratory, Justin Salamon, Adobe Research, Rachel Bittner, Research Scientist at Spotify, and Juan Pablo Bello, CDS affiliated Professor of Music Technology, Computer Science, and Engineering, and Director of the Music and Audio Research Lab, shared best practices for Open-Source Software (OSS) in MIR research. Drawing from expertise obtained over years of publishing their own open source software and open data within music research, the authors compiled a collection of tips spanning the development process. Notably, their suggestions are also relevant in other fields that employ complex systems.
As task complexity in MIR has increased, so too have the tools that researchers use. As a result, researchers underline the reality that seemingly minor differences in implementation can lead to reproducibility crises in MIR. Researchers can often access common datasets to obtain similar results. However, due to the nature of MIR datasets, which are often private or copyrighted, it is imperative that researchers meticulously describe implementation details to ensure reproducibility. Fundamentally, the publication provides a step-by-step guideline to conducting high quality MIR research so that it meets standards for reproducibility. Those interested in publishing research for the community at large could benefit from reviewing the standards appreciated and suggested by experienced and qualified professionals in the field.
Researchers outlined a few primary points of importance, then provided a visualization of typical MIR research processes (see Figure 1), outlining best practices at each stage. At any of the stages, leaving out critical information could compromise the reproducibility of the results. The first stage is data storage, followed by input decoding, synthesis and augmentation, data sampling, modeling, and deployment. McFee et al. provided specific suggestions at each stage that help to guarantee reproducibility.
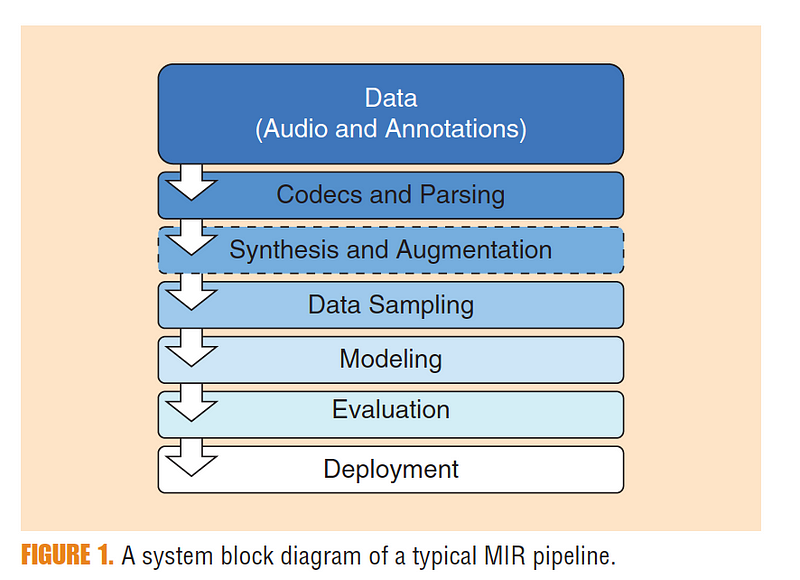
Beginning with data storage, researchers remark that storage methodology is integral to the system, as datasets grow. As for input decoding, researchers comment that there is currently no established MIR standard for encoding metadata and annotations. Regarding synthesis and augmentation, which refers to processes that artificially modify or expand data sets, researchers stress the importance of using modern frameworks like MUDA and Scaper to record precise methodology. Of sampling, researchers highlight stochastic sampling, warning that “Modern methods trained by stochastic gradient descent can be sensitive to initialization and sampling,” necessitating measures to ensure reproducibility. McFee et al. comment that modeling, including feature extraction and statistical modeling, can result in differing outcomes depending on which libraries are used. Once again, they emphasize the importance of “sharing specific software implementations.” Finally, in the deployment stage, researchers state that, “…software packaging emerges as an integral step to both internal reuse and scholarly disseminations,” and encourage their peers to involve themselves in this final stage. Researchers also conduct and document demonstrations of how incomplete descriptions can lead to differing outcomes. These examples underscore the ultimate task of this publication: to prevent complications in reproducibility after the deployment stage. Constructing reproducible research is critical to contributing to progress in MIR research tasks.
Further suggestions highlighted here include taking care to include a license, thereby ensuring the work will be available to those who intend to use, modify, or distribute it. Additionally, given that documentation is the “primary source of information for users of a particular piece of software,” McFee et al. suggest that documentation be completed concurrently with code, and that researchers use a build tool to automatically generate a website containing documentation details. Another key point McFee et al. consider is the utility to others in providing example code with documentation. Of course, Version Control Software (VCS) is essential to tracking the development process, and McFee et al. recommend GitHub for this purpose, and for managing releases. McFee et al. advocate also for automated software testing, which improves robustness and ensures utility. The subjects contained in the paper go on to discuss, in greater depth and breadth, best practices for those looking to contribute OSS to the MIR community at large. Ultimately, by publishing this guide, McFee et al. hope to “encourage future researchers to think carefully about data construction, preservation, and management issues moving forward.”
By Sabrina de Silva