On this page: Series Overview • Fall 2025 Seminars • Spring 2025 Seminars • Seminar Lecture Recordings • Past Seminars
Series Overview

The Math and Democracy Seminar unites researchers exploring the intersection of mathematical sciences and democratic structures. It aims to stimulate mathematical activity on democracy-related problems and foster collaboration between mathematicians, scholars from other disciplines, and democratic stakeholders.
The seminar’s scope is always evolving as new applications emerge.
Example Focus Areas:
- Gerrymandering detection
- Algorithmic fairness in social decision-making
- Voting and apportionment theory
- Statistical applications in discrimination law
- Census data analysis
- Mathematical modeling of democratic processes
Researchers, students, and practitioners interested in the mathematical underpinnings of democratic systems are welcome to attend. Those seeking more information or wishing to join the mailing list are encouraged to contact organizer Ben Blum-Smith at ben@cims.nyu.edu.
Fall 2025 Seminars
Zarina Dhillon, NYU Steinhart + Brennan Center: Evaluating Methods Used to Quantify Racial Segregation
Monday, November 24, 5:30-6:30pm, followed by 15 min Q&A, 650 (60 5th ave) and on Zoom
Abstract: Racial segregation has long been a problem in communities across the United States, and in understanding how it is quantified we enhance our ability to offer proposals for eradication. Many metrics have been developed for measurement, but none fully capture the nuances of this complicated issue: This work provides an overview of four mathematical approaches that have been developed to study segregation, explains how they function, and compares/contrasts their effectiveness in various situations in order to determine which best succeeds. An additional focus lies in a case study of Los Angeles (LA) County. It was found that attempts to further standardize outputs erases crucial data, and compressing this issue into one score is not representative of its complexity. This suggests that future exploration should attempt to study segregation more comprehensively rather than distilling an incredibly complicated and important issue into a single statistic.
Bio: Zarina Dhillon is earning her Masters in Applied Statistics with a concentration on data science for social impact. Zarina recently completed a year long Parke Research Fellowship in the Brennan Center for Justice’s Democracy Program, where she focused on voter turnout and political redistricting. She earned her Bachelors in Mathematics with honors from Claremont McKenna College as a proud transfer student from Santa Barbara City College, where she earned nine associates degrees spanning economics, philosophy, communications, psychology, and mathematics.
Zarina is passionate about using quantitative techniques in unique ways to contribute to the fight for justice, and holds accessibility and intersectionality at the core of her work. As a former professional dancer, Zarina loves to bring that creativity and artistry into her problem solving, and is excited to see how her non-linear background continues to enhance her endeavors.
Daphne Skipper: Geographic Access to Polling
Monday, November 10, 5:30-6:30pm, followed by 15 min Q&A, 650 (60 5th ave) and on Zoom
Abstract: Longer travel distances to polling places can discourage people from voting, and these effects tend to fall hardest on minority communities. In this talk, I will share a new approach for selecting polling sites that promote more equitable geographic access to voting. Our method does two things: it assesses how fair a given set of polling sites is, and it identifies the optimal set of sites to open from a list of possible locations. The key idea is to borrow a concept from the environmental justice literature, the Kolm–Pollak Equally Distributed Equivalent (EDE), which is designed to compare distributions of disamenities such as exposure to air pollution. By adapting this measure, we can strike a balance between minimizing the average distance to polls and improving access for residents who live farthest away. I will introduce the intuition behind the Kolm–Pollak EDE, show how it fits into an optimization model that scales to city- and county-level problems, and demonstrate its use through a case study of early voting sites in DeKalb County, Georgia, during the 2020, 2022, and 2024 elections.
Bio: Daphne Skipper is a mathematician and operations researcher specializing in combinatorial and global optimization. Her theoretical work examines nonlinear modeling structures that arise across a wide range of optimization problems, with the goal of providing practical insight into how these structures are handled in models and algorithms. She applies these insights to large, complex systems where better modeling translates into real-world impact. Some examples of her applied projects include maximizing the impact of pollution-mitigation efforts in the Chesapeake Bay watershed, optimizing gas mixing and network operations to better meet demand, and designing equitable facility-location models that balance efficiency with fairness. In this latter area, her work spans methodological development, equitable selection of election polling sites, and improving access to grocery stores in food deserts. Her research has appeared in leading journals such as Nature Communications, the Election Law Journal, and Mathematical Programming, reflecting her commitment to applying mathematical rigor to problems of societal importance. Daphne lives and works in Annapolis, Maryland.
Spring 2025 Seminars
Bailey Passmore (Human Rights Data Analysis Group): Public data & human rights
Monday, April 28, 5:30-6:30pm EST, followed by a 15 minute Q&A, Zoom Only
Abstract: For the last 30 years, the Human Rights Data Analysis Group (HRDAG) has been using statistics and data science to support human rights advocacy campaigns around the world. While our international work typically involves casualty counts and using advanced statistical techniques to estimate undocumented victims, our U.S. work often involves using public data to report human rights violations experienced by those who are still living. Now, the California Racial Justice Act of 2020 has opened up even more opportunities for us to contribute to campaigns for racial justice, particularly for those affected by racial bias in criminal legal proceedings. Since early 2024, HRDAG has been collaborating with public defenders to provide support for RJA claims for their clients. This led to our first time providing expert testimony in a U.S. courtroom in February 2025, when we presented and defended 3 simple statistics based on the District Attorney’s case data and county census data. Bailey will discuss the model HRDAG uses for obtaining and analyzing public data to address local human rights concerns, as well as their experience working on an RJA case.
Bio: Bailey has been a data scientist at the Human Rights Data Analysis Group (“HRDAG”) since January 2022. While at HRDAG, they have designed reproducible and transparent data processing streams that include a variety of tasks, such as scraping data from public transparency platforms, extracting structured data from unstructured document collections, extracting key information from text data using LLMs, database deduplication and entity resolution, version resolution, and producing statistical analyses that speak to patterns of racial bias.
Prior to their position at HRDAG, Bailey worked as an undergraduate Data Science and Research Consultant for the San Diego Supercomputer Center, where they mined, cleaned, and analyzed system performance data and prepared the findings for the Practice and Experience in Advanced Research Computing (PEARC) conferences.
Bailey graduated from the University of California, San Diego with a bachelor of science degree in Cognitive Science, after transferring with a background in Mathematics and Computer Science.
Matthew Dahl (Yale University): Large Legal Fictions: Detecting Legal Hallucinations in Large Language Models
Monday, March 31, 5:30-6:30pm EST, followed by a 15 minute Q&A, Center for Data Science, 60 5th Ave, Room 650 and on Zoom (contact organizers for Zoom details)
Abstract: Do large language models (LLMs) know the law? LLMs are increasingly being used to augment legal practice, but their revolutionary potential is threatened by the presence of legal “hallucinations” — textual output that is not consistent with the content of the law. In this talk, I theorize the provenance and nature of these hallucinations and discuss methods for detecting them in LLM outputs. I then share results from three experiments auditing off-the-shelf LLMs and industry retrieval-augmented generation (RAG) models, showing that legal errors remain widespread. I conclude by emphasizing the need for empirical evidence in an age of ever-increasing hype about AI’s ability to replace lawyers and expand access to justice.
Bio: Matthew Dahl is a JD/PhD student at Yale Law School and Yale Department of Political Science. His research on AI, judicial behavior, and legal citation analysis has been published in the Journal of Empirical Legal Studies and the Journal of Legal Analysis. Before coming to Yale, he was a Fair Housing Fellow at Brancart & Brancart and received his BA from Pomona College.
Lalitha Sankar (Arizona State University): Understanding Last Layer Retraining Methods for Fair Classification: Theory and Algorithms
Monday, February 24, 5:30-6:30pm EST, followed by a 15 minute Q&A, Center for Data Science, NYU, 60 5th Ave, Room 650 and Zoom
Abstract: Last-layer retraining (LLR) methods have emerged as an efficient framework for ensuring fairness and robustness in deep models. In this talk, we present an overview of existing methods and provide theoretical guarantees for several prominent methods. Under the threat of label noise, either in the class or domain annotations, we show that these naive methods fail. To address these issues, we present a new robust LLR method in the framework of two-stage corrections and demonstrate that it achieves state-of-the-art performance under domain label noise with minimal data overhead. Finally, we demonstrate that class label noise causes catastrophic failures even with robust two-stage methods, and propose a drop-in label correction which outperforms existing methods with very low computational and data cost.
Bio: Lalitha Sankar is a Professor in the School of Electrical, Computer and Energy Engineering at Arizona State University. She joined ASU as an assistant professor in fall of 2012, and was an associate professor from 2018-2023. She received a bachelor’s degree from the Indian Institute of Technology, Bombay, a master’s degree from the University of Maryland, and a doctorate from Rutgers University in 2007. Following her doctorate, Sankar was a recipient of a three-year Science and Technology Teaching Postdoctoral Fellowship from the Council on Science and Technology at Princeton University, following which she was an associate research scholar at Princeton. Prior to her doctoral studies, she was a senior member of technical staff at AT&T Shannon Laboratories.
Sankar’s research interests are at the intersection of information and data sciences including a background in signal processing, learning theory, and control theory with applications to the design of machine learning algorithms with algorithmic fairness, privacy, and robustness guarantees. Her research also applies such methods to complex networks including the electric power grid and healthcare systems.
For her doctoral work, she received the 2007-2008 Electrical Engineering Academic Achievement Award from Rutgers University. She received the IEEE Globecom 2011 Best Paper Award for her work on privacy of side-information in multi-user data systems. She was awarded the National Science Foundation CAREER award in 2014 for her project on privacy-guaranteed distributed interactions in critical infrastructure networks such as the Smart Grid. She has led an NSF Institute on Data-intensive Research in Science and Engineering (I-DIRSE), is a recipient of an NSF SCALE MoDL (Mathematics of Deep Learning) grant, and a Google AI for Social Good grant. Sankar was a distinguished lecturer for the IEEE Information Theory Society from 2020-2022. She serves as an Associate Editor for the IEEE Transactions on Information Forensics and Security, IEEE Information Theory Transactions, and was an AE for the IEEE BITS Magazine until August 2024.
Seminar Lecture Recordings



Dimensionality reduction reveals dependence of voter polarization on political context
Sam Wang, Princeton University and Electoral Innovation Lab
Quantifying Communities of Interest in Electoral Redistricting
Ranthony Edmonds, Duke University and Parker Edwards, Florida Atlantic University
Date & Time: Monday, November 6, 2023
Title: Quantifying Communities of Interest in Electoral Redistricting
Abstract: Communities of interest are groups of people, such as ethnic, racial, and economic groups, with common sets of concerns that may be affected by legislation. Many states have requirements to preserve communities of interest as part of their redistricting process. While some states collect data about communities of interest in the form of public testimony, there are no states to our knowledge which systematically collect, aggregate, and summarize spatialized testimony on communities of interest when drawing new districting plans.
During the 2021 redistricting cycle, our team worked to quantify communities of interest by collecting and synthesizing thousands of community maps in partnership with grassroots organizations and/or government offices. In most cases, the spatialized testimony collected included both geographic and semantic data–a spatial representation of a community as a polygon, as well as a written narrative description of that community. In this talk, we outline our aggregation pipeline that started with spatialized testimony as input, and output processed community clusters for a given state with geographic and semantic cohesion.
Bio: Dr. Ranthony A.C. Edmonds is a Berlekamp Postdoctoral Researcher at the Simons Laufer Mathematical Sciences Institute affiliated with the Department of Mathematics at Duke University. She earned a PhD in Mathematics in 2018 from the University of Iowa, an MS in Mathematical Sciences from Eastern Kentucky University in 2013, and a BA in English and a BS in Mathematics from the University of Kentucky in 2011. Her research interests include applied algebraic topology, data science, commutative ring theory, and mathematics education. She is deeply invested in quantitative justice, that is, using mathematical tools to address societal issues rooted in inequity. Her current work in quantitative justice involves applications of mathematics and statistics to electoral redistricting.
Dr. Parker Edwards is an Assistant Professor in the Department of Mathematical Sciences at Florida Atlantic University. His research focuses on both theory and applications for combining machine learning with tools from computational algebraic topology and geometry to analyze complex and high-dimensional data sets. He received a PhD in Mathematics from the University of Florida in 2020 and MSc in Mathematics and the Foundations of Computer Science from the University of Oxford in 2016.

Ranked Choice Voting and the Spoiler Effect
Jennifer Wilson, The New School and David McCune, William Jewell College
Date & Time: Monday, November 7, 2022
Title: Ranked Choice Voting and the Spoiler Effect
Abstract: One of the advantages commonly cited about Ranked Choice Voting is that it prevents spoilers from affecting the outcome of an election. In this talk we will discuss what a spoiler is and how it can be defined mathematically. Then we will examine how ranked choice voting performs relative to plurality voting based on this definition. We will approach this theoretically, assuming impartial, anonymous culture and independent culture models; through simulation using both random and single-peaked models; and empirically, based on an analysis of a large database of American ranked choice elections. All of these confirm that ranked choice voting is superior to plurality based on the likelihood of the spoiler effect occurring.
Bio: Jennifer Wilson is Associate Professor of Mathematics at Eugene Lang College, The New School. She works in the areas of social choice theory, resource allocation, and mathematics applied to the social sciences more generally. She is interested in the intersection of discrete and continuous problems, and most recently has been investigating, with David McCune and Michael A. Jones, the delegate allocation process in the US presidential primaries.
David McCune is an Associate Professor of Mathematics at William Jewell College in Liberty, MO. He mostly works on problems in social choice theory and apportionment theory, with an emphasis on the computational and empirical side of things.

Diversity and inequality in social networks
Ana-Andreea Stoica, Columbia University
Date & Time: Monday, March 28, 2022
Title: Diversity and inequality in social networks
Abstract: Online social networks often mirror inequality in real-world networks, from historical prejudice, economic or social factors. Such disparities are often picked up and amplified by algorithms that leverage social data for the purpose of providing recommendations, diffusing information, or forming groups. In this talk, I discuss an overview of my research involving explanations for algorithmic bias in social networks, briefly describing my work in information diffusion, grouping, and general definitions of inequality. Using network models that reproduce inequality seen in online networks, we’ll characterize the relationship between pre-existing bias and algorithms in creating inequality, discussing different algorithmic solutions for mitigating bias.
Bio: Ana-Andreea Stoica is a Ph.D. candidate at Columbia University. Her work focuses on mathematical models, data analysis, and inequality in social networks. From recommendation algorithms to the way information spreads in networks, Ana is particularly interested in studying the effect of algorithms on people’s sense of community and access to information and opportunities. She strives to integrate tools from mathematical models—from graph theory to opinion dynamics—with sociology to gain a deeper understanding of the ethics and implications of technology in our everyday lives. Ana grew up in Bucharest, Romania, and moved to the US for college, where she graduated from Princeton in 2016 with a bachelor’s degree in Mathematics. Since 2019, she has been co-organizing the Mechanism Design for Social Good initiative.

Quantifying Gerrymandering: Advances in Sampling Graph Partitions from Policy-Driven Measures
Gregory Herschlag, Duke University
Date & Time: Monday, December 13, 2021
Title: Quantifying Gerrymandering: Advances in Sampling Graph Partitions from Policy-Driven Measures
Abstract: Gerrymandering is the process of manipulating political districts either to amplify the power of a political group or suppress the representation of certain demographic groups. Although we have seen increasingly precise and effective gerrymanders, a number of mathematicians, political scientists, and lawyers are developing effective methodologies at uncovering and understanding the effects of gerrymandered districts.
The basic idea behind these methods is to compare a given set of districts to a large collection of neutrally drawn plans. The process relies on three distinct components: First, we determine rules for compliant redistricting plans along with codifying preferences between these plans; next, we sample the space of compliant redistricting plans (according to our preferences) and generate a large collection of non-partisan alternatives; finally, we compare the collection of plans to a particular plan of interest. The first step, though largely a legal question of compliance, provides interesting grounds for mathematical translation between policies and probability measures; the second and third points create rich problems in the fields of applied mathematics (sampling theory) and data analysis, respectively.
In this talk, I will discuss how our research group at Duke has analyzed gerrymandering. I will discuss the sampling methods we employ and discuss several recent algorithmic advances. I will also mention several open problems and challenges in this field. These sampling methods provide rich grounds both for mathematical exploration and development and also serve as a practical and relevant algorithm that can be employed to establish and maintain fair governance.
Bio: Gregory Herschlag received his Ph.D. in mathematics from UNC Chapel Hill in 2013. Since then, he has been in a research position at Duke University that has spanned both the Departments of Biomedical Engineering and Mathematics. He began working with Jonathan Mattingly on algorithms to quantify gerrymandering in 2016; within this collaboration, Greg has analyzed and quantified gerrymandering in the North Carolina congressional districts, the Wisconsin general assembly, and the North Carolina legislature, and more. This work was incorporated into expert testimony in Common Cause v. Rucho, North Carolina v. Covington, and was featured in an Amicus brief submitted to the Supreme Court during Gill v. Whitford. He has also developed several new algorithms to sample and understand the space of redistricting plans. These algorithms are currently being employed to analyze and audit plans in the 2020 redistricting cycle.

Colorado in Context: A case study in mathematics and fair redistricting in Colorado
Jeanne Clelland, University of Colorado Boulder and Beth Malmskog, Colorado College
Date & Time: Monday, November 1, 2021
Title: Colorado in Context: A case study in mathematics and fair redistricting in Colorado
Abstract: How do we measure or identify partisan bias in the boundaries of districts for elected representatives? What outcomes are potentially “fair” for a given region depends intimately on its particular human and political geography. Ensemble analysis is a mathematical/statistical technique for putting potential redistricting maps in context of what can be expected for maps drawn without partisan data. This talk will introduce the basics of ensemble analysis, describe some recent advances in creating representative ensembles and quantifying mixing, and discuss how our research group has applied the technique in Colorado both in an academic framework and as consultants to the 2021 Independent Legislative Redistricting Commission.
Bio: Dr. Jeanne Clelland is a Professor in the Department of Mathematics at University of Colorado Boulder. She received her Ph.D. from Duke University in 1996 and completed a National Science Foundation Postdoctoral Research Fellowship at the Institute for Advanced Study prior to joining the faculty at CU-Boulder in 1998. Her research focuses on differential geometry and applications of geometry to the study of differential equations, and more recently on mathematical topics related to redistricting. Dr. Clelland is the author of the textbook From Frenet to Cartan: The Method of Moving Frames, and she is the 2018 winner of the Burton W. Jones Distinguished Teaching Award from the Rocky Mountain Section of the Mathematical Association of America.
Dr. Beth Malmskog is an assistant professor in the Department of Mathematics and Computer Science at Colorado College. Her research is in number theory, algebraic geometry, and applied discrete mathematics. She began working on mathematical aspects of fair redistricting in 2019. Dr. Malmskog earned her PhD at Colorado State University. She serves on the Board of Directors for the League of Women Voters of Colorado.

The Topology of Redistricting
Thomas Weighill, UNC Greensboro
Date & Time: Monday, Oct. 4, 2021
Title: The Topology of Redistricting
Abstract: Across the nation, legislatures and commissions are deciding where the Congressional districts in their state will be for the next decade. Even under standard constraints such as contiguity and population balance, they will have exponentially many possible maps to choose from. Recent computational advances have nonetheless made it possible to robustly sample from this vast space of possibilities, exposing the question of what a typical map looks like to data analysis techniques. In this talk I will show how topological data analysis (TDA) can help cut through the complexity and uncover key political features of redistricting in a given state. This is joint work with Moon Duchin and Tom Needham.
Bio: Thomas Weighill is an Assistant Professor at the University of North Carolina at Greensboro. He received his PhD from the University of Tennessee, after which he was a postdoc at the MGGG Redistricting Lab at Tufts University. His research focuses on geometry and topology and their applications to data science, particularly to Census and election data.
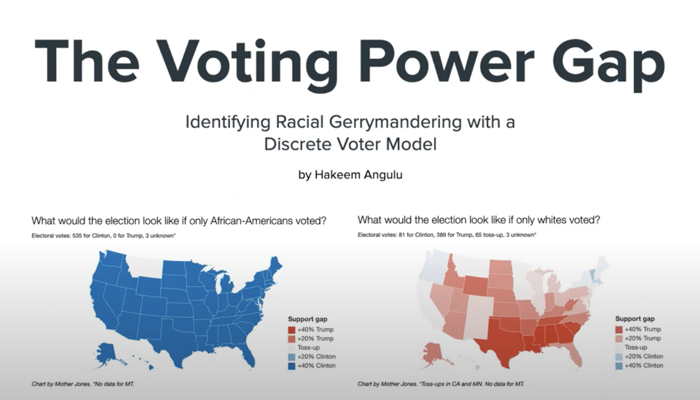
The Voting Power Gap: Identifying Racial Gerrymandering with a Discrete Voter Model
Hakeem Angulu, Google and MGGG Redistricting Lab @ Tufts
Date & Time: Monday, May 10, 2021
Title: The Voting Power Gap: Identifying Racial Gerrymandering with a Discrete Voter Model
Abstract: Section 2 of the Voting Rights Act of 1965 (VRA) prohibits voting practices or procedures that discriminate based on race, color, or membership in a language minority group, and is often cited by plaintiffs seeking to challenge racially-gerrymandered districts in court.
In 1986, with Thornburg v. Gingles, the Supreme Court held that in order for a plaintiff to prevail on a section 2 claim, they must show that:
In the 1990s and early 2000s, Professor Gary King’s ecological inference method tackled the second condition: racially polarized voting, or racial political cohesion. His technique became the standard technique for analyzing racial polarization in elections by inferring individual behavior from group-level data. However, for more than 2 racial groups or candidates, that method hits computational bottlenecks.
- the racial or language minority group is sufficiently numerous and compact to form a majority in a single-member district
- that group is politically cohesive
- and the majority votes sufficiently as a bloc to enable it to defeat the minority’s preferred candidate
All three conditions are notoriously hard to show, given the lack of data on how people vote by race.
A new method of solving the ecological inference problem, using a mixture of contemporary statistical computing techniques, is demonstrated with this work. It is called the Discrete Voter Model. It can be used for multiple racial groups and candidates, and has been shown to work well on randomly-generated mock election data.
Bio: Hakeem Angulu is a software engineer at Google, where he works on solutions to misinformation and disinformation within Google News. Hakeem graduated from Harvard College with a joint concentration in Computer Science and Statistics, with a secondary in African American Studies. Outside of work, he continues research into solutions for gerrymandering using computational and statistical tools, and he is the CTO of Oak, a startup committed to uplifting Black-owned hair businesses and making natural hair accessible using science and technology.

Statistical aspects of algorithmic fairness
Joshua Loftus, New York University
Date & Time: Wednesday, February 12, 2020
Title: Statistical aspects of algorithmic fairness
Abstract: The social impact of technology has recently generated a lot of work in the machine learning research community, but relatively little from statistics. Fundamental issues such as fairness, privacy, and even legal rights such as the right to an “explanation” of an automated decision can not be reduced to properties of a given dataset and learning algorithm, but must account for statistical aspects of the data generating process. In this talk I will survey some recent literature on algorithmic fairness with a focus on methods based on causal inference. One such approach, counterfactual fairness, requires that predictions or decisions be the same both in the actual world and in a counterfactual world where an individual had a different value of a sensitive attribute, such as race or gender. This approach defines fairness in the context of a causal model for the data which usually relies on untestable assumptions. The causal modeling approach is useful for thinking about the implicit assumptions or possible consequences of other definitions, and identifying key points for interventions.
Bio: Joshua R. Loftus joined New York University Stern School of Business as an Assistant Professor of Information, Operations and Management Sciences in September 2017. Professor Loftus studies statistical methodology for machine learning and data science pipelines with a focus on addressing sources and types of error that were previously overlooked. This includes developing methods for inference after model selection that account for selection bias and analyzing fairness of the impact of algorithms on people from a causal perspective. His work has been published in the Annals of Statistics, Biometrika, Advances in Neural Information Processing Systems, and the International Conference on Machine Learning. Before joining NYU Stern, Professor Loftus was a Research Fellow at the Alan Turing Institute, affiliated with the University of Cambridge. Professor Loftus earned a B.S. in Mathematics at Western Michigan University, an M.S. in Mathematics at Rutgers University, and a Ph.D. in Statistics at Stanford University.
Past Seminars
Below you’ll find an archive of information on our seminar lectures dating back to the beginning of the series.
Spring 2024
Speaker: Abigail Hickok, Columbia University, and Mason Porter, UCLA
Date & Time: Monday, May 6, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: 60 5th Ave, 7th floor open space, and on Zoom — contact seminar organizers for details
Title: Topological Data Analysis of Voting-Site Coverage
Abstract: In many cities in the United States, it can take a very long time to go to a polling site to cast a vote in an election. To find such “voting deserts” in an algorithmic way, we use persistent homology (PH), which is a type of topological data analysis (TDA) that allows one to detect “holes” in data. In this talk, we’ll give an introduction to TDA and PH. We will then discuss our recent work on PH to detect voting deserts and in the coverage of other resources.
Bio: Abigail Hickok is an NSF postdoctoral fellow in the Department of Mathematics at Columbia University. Prior to joining Columbia, she completed a PhD in applied mathematics at UCLA in 2023, and she received her undergraduate degree in mathematics at Princeton in 2018. Her research is on the theory and applications of geometric and topological data analysis.
Mason Porter is a professor in the Department of Mathematics at University of California, Los Angeles (UCLA). He earned a B.S. in Applied Mathematics from Caltech in 1998 and a Ph.D. from the Center for Applied Mathematics at Cornell University in 2002. Mason held postdoctoral positions at Georgia Tech, the Mathematical Sciences Research Institute, and California Institute of Technology (Caltech). He joined as faculty at University of Oxford in 2007 and moved to UCLA in 2016. Mason is a Fellow of the American Mathematical Society, the American Physical Society, and the Society for Industrial and Applied Mathematics. In recognition of his mentoring of undergraduate researchers, Mason won the 2017 Council on Undergraduate Research (CUR) Faculty Mentoring Award in the Advanced Career Category in the Mathematics and Computer Science Division. To date, 26 students have completed their Ph.D. degrees under Mason’s mentorship, and Mason has also mentored several postdocs, more than 30 masters students, and more than 100 undergraduate students on various research projects. Mason’s research interests lie in theory and (rather diverse) applications of networks, complex systems, and nonlinear systems.
Speaker: Cory McCartan, NYU CDS
Date & Time: Monday, May 13, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: 60 5th Ave, Room 650, and on Zoom — contact seminar organizers for details
Title: Estimating Racial Disparities When Race is Not Observed
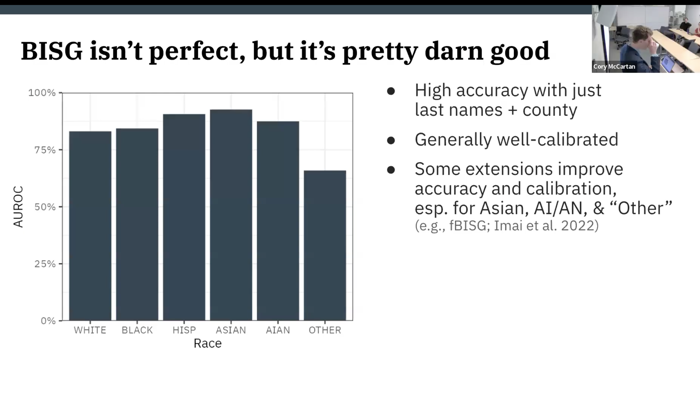
Abstract: Discovering and quantifying racial disparities is critical to ensuring equitable distribution of public goods and services, and building fair decision-making algorithms and processes. But in many important contexts, data about race is not available at the individual level. Methods exist to predict individuals’ race from attributes like their name and location, but these tools create their own set of statistical challenges, which if not addressed can significantly understate or overstate the size of racial disparities. This talk will discuss these challenges and introduce new methodology to address them, allowing for accurate inference of racial disparities in datasets without racial information. The authors have worked with the U.S. Treasury Department to apply the new method to millions of individual tax returns to estimate disparities in who claims the home mortgage interest deduction, the most expensive individual deduction in the federal tax code.
Bio: Cory McCartan is a Faculty Fellow at CDS and will join the Penn State Department of Statistics in July. He works on methodological and applied problems in the social sciences, including gerrymandering, electoral reform, privacy of public data, and racial disparities.
Spring 2023
Speaker: Sunoo Park, Columbia University
Date & Time: Monday, April 24, 2023, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: Scan, Shuffle, Rescan: Two-Prover Election Audits With Untrusted Scanners
Abstract: We introduce a new way to conduct election audits using untrusted scanners. Post-election audits perform statistical hypothesis testing to confirm election outcomes. However, existing approaches are costly and laborious for close elections—often the most important cases to audit— requiring extensive hand inspection of ballots. We instead propose automated consistency checks, augmented by manual checks of only a small number of ballots. Our protocols scan each ballot twice, shuffling the ballots between scans: a “two-scan” approach inspired by two-prover proof systems. We show that this gives strong statistical guarantees even for close elections, provided that (1) the permutation accomplished by the shuffle is unknown to the scanners and (2) the scanners cannot reliably identify a particular ballot among others cast for the same candidate. Our techniques could drastically reduce the time, expense, and labor of auditing close elections, which we hope will promote wider deployment. Joint work with Douglas W. Jones, Ronald L. Rivest, and Adam Sealfon.
Bio: Sunoo Park is a postdoctoral fellow at Columbia University and visiting fellow at Columbia Law School. Her research is in security, cryptography, privacy, and related law/policy issues. She received her J.D. at Harvard Law School, her Ph.D. in computer science at MIT, and her B.A. in computer science from the University of Cambridge.
Speaker: Ranthony Edmonds, Ohio State University and Parker Edwards, University of Notre Dame
Date & Time: Monday, April 10, 2023, 5:30-6:30pm ET, followed by a 15 minute Q&A CANCELED
Place: Zoom meeting — contact seminar organizers for details
Title: Quantifying Communities of Interest in Electoral Redistricting
Abstract: Communities of interest are groups of people, such as ethnic, racial, and economic groups, with common sets of concerns that may be affected by legislation. Many states have requirements to preserve communities of interest as part of their redistricting process. While some states collect data about communities of interest in the form of public testimony, there are no states to our knowledge which systematically collect, aggregate, and summarize spatialized testimony on communities of interest when drawing new districting plans.
During the 2021 redistricting cycle, our team worked to quantify communities of interest by collecting and synthesizing thousands of community maps in partnership with grassroots organizations and/or government offices. In most cases, the spatialized testimony collected included both geographic and semantic data–a spatial representation of a community as a polygon, as well as a written narrative description of that community. In this talk, we outline our aggregation pipeline that started with spatialized testimony as input, and output processed community clusters for a given state with geographic and semantic cohesion.
Bio: Dr. Ranthony A.C. Edmonds is an National Science Foundation Postdoctoral Researcher of Mathematics affiliated with the Department of Mathematics at The Ohio State University. She earned a PhD in Mathematics in 2018 from the University of Iowa, an MS in Mathematical Sciences from Eastern Kentucky University in 2013, and a BA in English and a BS in Mathematics from the University of Kentucky in 2011. Her research interests include applied algebraic topology, data science, commutative ring theory, and mathematics education. She is deeply invested in quantitative justice, that is, using mathematical tools to address societal issues rooted in inequity. Her current work in quantitative justice involves applications of mathematics and statistics to electoral redistricting and policing data from small towns.
Dr. Parker Edwards is a Robert and Sara Lumpkins Postdoctoral Research Associate in the Department of Applied & Computational Mathematics & Statistics at the University of Notre Dame. His research focuses on both theory and applications for combining machine learning with tools from computational algebraic topology and geometry to analyze complex and high-dimensional data sets. He received a PhD in Mathematics from the University of Florida in 2020 and MSc in Mathematics and the Foundations of Computer Science from the University of Oxford in 2016.
Speaker: Marion Campisi, San José State University
Date & Time: March 6, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: The Geometry and Election Outcome (GEO) Metric
Abstract: We introduce the Geography and Election Outcome (GEO) metric, a new method for identifying potential partisan gerrymanders. In contrast with currently popular methods, the GEO metric uses both geographic information about a districting plan as well as district-level partisan data, rather than just one or the other. We motivate and define the GEO metric, which gives a count (a non-negative integer) to each political party. The count indicates the number of previously lost districts which that party potentially could have had a 50% chance of winning, without risking any currently won districts, by making reasonable changes to the input map. We then analyze GEO metric scores for each party in several recent elections. We show that this relatively easy to understand and compute metric can encapsulate the results from more elaborate analyses.
Bio: Marion Campisi is an Associate Professor in the department of Mathematics and Statistics at San José State University. Her research interests lie in low dimensional topology, knot theory and the mathematics of redistricting.
Fall 2023
Speaker: Sam Wang, Princeton University and Electoral Innovation Lab
Time: Wednesday, December 13, 5:30-6:30pm ET, followed by a 15 minute Q&A (note unusual day)
Place: CDS, 60 5th Ave, 7th floor open space, and on Zoom (zoom details to follow)
Title: Dimensionality reduction reveals dependence of voter polarization on political context
Abstract: Political dynamics in the U.S. have become highly polarized, despite the fact that individual voters can have complex views. To capture the dimensionality of how voters express their preferences, we are analyzing over 400 ranked-choice elections, in which voters rank candidates in order of preference. We find that most voters act as if they share a representation of candidates on a single axis. Voters each have a place on that axis, in the aggregate defining a spectrum of simple political behavior. Voter spectra are more bimodal for executive and federal offices than for local offices, suggesting that polarization of voter behavior is strongly shaped by available choices. We are now investigating how candidate and voter behavior may be shaped by incentives arising from ranked-choice voting and other reforms. Such shaping would suggest practical strategies to reduce political polarization.
Bio: Sam Wang has been a professor at Princeton University since 2000, and director of the Electoral Innovation Lab since 2020. He holds a B.S. in physics from the California Institute of Technology and a Ph.D. in neuroscience from Stanford University. He has published over 100 articles spanning neuroscience, elections, and democracy reform. A central feature of his research is the use and development of statistical tools for dealing with large, complex data sets. In 2004, he pioneered methods for the aggregation of state polls to predict U.S. presidential elections. In 2012 he recognized new, systematic distortions in representation in the U.S. House, leading to the creation of the Princeton Gerrymandering Project. In 2020 these projects were subsumed into the Electoral Innovation Lab, whose mission is to create and apply a practical science of democracy reform.
Speaker: Ranthony Edmonds, Duke University and Parker Edwards, Florida Atlantic University
Date & Time: Monday, November 6, 5:45-6:45pm ET, followed by a 15 minute Q&A
Place: Zoom webinar — contact seminar organizers for details
Title: Quantifying Communities of Interest in Electoral Redistricting
Abstract: Communities of interest are groups of people, such as ethnic, racial, and economic groups, with common sets of concerns that may be affected by legislation. Many states have requirements to preserve communities of interest as part of their redistricting process. While some states collect data about communities of interest in the form of public testimony, there are no states to our knowledge which systematically collect, aggregate, and summarize spatialized testimony on communities of interest when drawing new districting plans.
During the 2021 redistricting cycle, our team worked to quantify communities of interest by collecting and synthesizing thousands of community maps in partnership with grassroots organizations and/or government offices. In most cases, the spatialized testimony collected included both geographic and semantic data–a spatial representation of a community as a polygon, as well as a written narrative description of that community. In this talk, we outline our aggregation pipeline that started with spatialized testimony as input, and output processed community clusters for a given state with geographic and semantic cohesion.
Bio: Dr. Ranthony A.C. Edmonds is a Berlekamp Postdoctoral Researcher at the Simons Laufer Mathematical Sciences Institute affiliated with the Department of Mathematics at Duke University. She earned a PhD in Mathematics in 2018 from the University of Iowa, an MS in Mathematical Sciences from Eastern Kentucky University in 2013, and a BA in English and a BS in Mathematics from the University of Kentucky in 2011. Her research interests include applied algebraic topology, data science, commutative ring theory, and mathematics education. She is deeply invested in quantitative justice, that is, using mathematical tools to address societal issues rooted in inequity. Her current work in quantitative justice involves applications of mathematics and statistics to electoral redistricting.
Dr. Parker Edwards is an Assistant Professor in the Department of Mathematical Sciences at Florida Atlantic University. His research focuses on both theory and applications for combining machine learning with tools from computational algebraic topology and geometry to analyze complex and high-dimensional data sets. He received a PhD in Mathematics from the University of Florida in 2020 and MSc in Mathematics and the Foundations of Computer Science from the University of Oxford in 2016.
Spring 2022
Speaker: Ana-Andreea Stoica, Columbia University
Recording: View Ana-Andreea Stoica Lecture Recording
Date & Time: Monday, March 28, 5:30-6:30pm, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: Diversity and inequality in social networks
Abstract: Online social networks often mirror inequality in real-world networks, from historical prejudice, economic or social factors. Such disparities are often picked up and amplified by algorithms that leverage social data for the purpose of providing recommendations, diffusing information, or forming groups. In this talk, I discuss an overview of my research involving explanations for algorithmic bias in social networks, briefly describing my work in information diffusion, grouping, and general definitions of inequality. Using network models that reproduce inequality seen in online networks, we’ll characterize the relationship between pre-existing bias and algorithms in creating inequality, discussing different algorithmic solutions for mitigating bias.
Bio: Ana-Andreea Stoica is a Ph.D. candidate at Columbia University. Her work focuses on mathematical models, data analysis, and inequality in social networks. From recommendation algorithms to the way information spreads in networks, Ana is particularly interested in studying the effect of algorithms on people’s sense of community and access to information and opportunities. She strives to integrate tools from mathematical models—from graph theory to opinion dynamics—with sociology to gain a deeper understanding of the ethics and implications of technology in our everyday lives. Ana grew up in Bucharest, Romania, and moved to the US for college, where she graduated from Princeton in 2016 with a bachelor’s degree in Mathematics. Since 2019, she has been co-organizing the Mechanism Design for Social Good initiative.
Speaker: Daryl DeFord, Washington State University
Date & Time: Monday, March 7, 5:30-6:30pm, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: Partisan Dislocation, Competitiveness, and Designing Ensembles for Redistricting Analysis
Abstract: Computational redistricting techniques are playing an increasingly large role in the analysis and design of districting plans for legislative elections. In this talk I will discuss recent work using Markov chain ensembles to evaluate tradeoffs between redistricting criteria and a new measure, partisan dislocation, that evaluates plans by directly incorporating political geography. Throughout, I will demonstrate how examples of these methods in court cases, reform efforts, and map construction highlight the important interplay between mathematics, computational methods, political science, and the law.
Bio: Dr. DeFord is an Assistant Professor of Data Analytics in the Department of Mathematics and Statistics at Washington State University. His research work focuses on applications of mathematical techniques to computational redistricting and other problems arising from network models of social data. Before joining the faculty as WSU, Dr. DeFord was a postdoctoral associate in the Geometric Data Processing Group in CSAIL at MIT, supervised by Dr. Justin Solomon, and affiliated with the Metric Geometry and Gerrymandering Group at Tufts, supervised by Dr. Moon Duchin. He completed his Ph.D. on dynamical models for multiplex networks at Dartmouth College, advised by Dr. Dan Rockmore.
Fall 2022
Speaker: Jayshree Sarathy, Harvard University
Date & Time: Monday, November 21, 2022, 5:30-6:30pm ET
Place: Zoom meeting — contact seminar organizers for details
Title: Distrust in Noisy Numbers: Epistemic Disconnects Surrounding the Use of Differential Privacy in the 2020 U.S. Census
Abstract: For decades, the U.S. Census Bureau has used disclosure avoidance techniques in order to protect the confidentiality of individuals represented in census data. Yet, the Census Bureau’s modernization of its disclosure avoidance procedures for its 2020 Census triggered a controversy that is still underway. In this talk, I argue that the move to differential privacy exposed epistemic disconnects around what we identify as a “statistical imaginary,” destabilizing a network of practitioners that upholds the legitimacy of census data. I end by raising questions about how we can—and must—re-imagine our statistical infrastructures going forward.
Bio: Jayshree Sarathy is a 5th year PhD student in Computer Science (and Science & Technology Studies) at Harvard University. She is part of the Theory of Computation group and OpenDP project, and is currently a graduate fellow with the Harvard Edmond & Lily Safra Center for Ethics. Her research explores the complexities of privacy and data access within socio-technical systems.
Speaker: Jennifer Wilson, The New School and David McCune, William Jewell College
Recording: View Jennifer Wilson and David McCune Lecture Recording
Date & Time: Monday, November 7, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: Ranked Choice Voting and the Spoiler Effect
Abstract: One of the advantages commonly cited about Ranked Choice Voting is that it prevents spoilers from affecting the outcome of an election. In this talk we will discuss what a spoiler is and how it can be defined mathematically. Then we will examine how ranked choice voting performs relative to plurality voting based on this definition. We will approach this theoretically, assuming impartial, anonymous culture and independent culture models; through simulation using both random and single-peaked models; and empirically, based on an analysis of a large database of American ranked choice elections. All of these confirm that ranked choice voting is superior to plurality based on the likelihood of the spoiler effect occurring. Bio: Jennifer Wilson is Associate Professor of Mathematics at Eugene Lang College, The New School. She works in the areas of social choice theory, resource allocation, and mathematics applied to the social sciences more generally. She is interested in the intersection of discrete and continuous problems, and most recently has been investigating, with David McCune and Michael A. Jones, the delegate allocation process in the US presidential primaries. David McCune is an Associate Professor of Mathematics at William Jewell College in Liberty, MO. He mostly works on problems in social choice theory and apportionment theory, with an emphasis on the computational and empirical side of things.
Spring 2021
Speaker: Hakeem Angulu, Google and MGGG Redistricting Lab @ Tufts
Recording: View Hakeem Angulu Lecture Recording
Date & Time: May 10, 5:30-6:30p ET
Title: The Voting Power Gap: Identifying Racial Gerrymandering with a Discrete Voter Model
Abstract: Section 2 of the Voting Rights Act of 1965 (VRA) prohibits voting practices or procedures that discriminate based on race, color, or membership in a language minority group, and is often cited by plaintiffs seeking to challenge racially-gerrymandered districts in court.
In 1986, with Thornburg v. Gingles, the Supreme Court held that in order for a plaintiff to prevail on a section 2 claim, they must show that:
In the 1990s and early 2000s, Professor Gary King’s ecological inference method tackled the second condition: racially polarized voting, or racial political cohesion. His technique became the standard technique for analyzing racial polarization in elections by inferring individual behavior from group-level data. However, for more than 2 racial groups or candidates, that method hits computational bottlenecks.
- the racial or language minority group is sufficiently numerous and compact to form a majority in a single-member district
- that group is politically cohesive
- and the majority votes sufficiently as a bloc to enable it to defeat the minority’s preferred candidate
All three conditions are notoriously hard to show, given the lack of data on how people vote by race.
A new method of solving the ecological inference problem, using a mixture of contemporary statistical computing techniques, is demonstrated with this work. It is called the Discrete Voter Model. It can be used for multiple racial groups and candidates, and has been shown to work well on randomly-generated mock election data.
Bio: Hakeem Angulu is a software engineer at Google, where he works on solutions to misinformation and disinformation within Google News. Hakeem graduated from Harvard College with a joint concentration in Computer Science and Statistics, with a secondary in African American Studies. Outside of work, he continues research into solutions for gerrymandering using computational and statistical tools, and he is the CTO of Oak, a startup committed to uplifting Black-owned hair businesses and making natural hair accessible using science and technology.
Speaker: Michael Orrison, Harvey Mudd College
Date & Time: April 26, 5:30-6:30p ET
Title: Voting and Linear Algebra: Connections and Questions
Abstract: Voting is something we do in a variety of settings and in a variety of ways, but it can often be difficult to see nontrivial relationships between the different voting procedures we use. In this talk, I will discuss how simple ideas from linear algebra and discrete mathematics can sometimes be used to unify different voting procedures, and how doing so leads to new insights and new questions in voting theory.
Bio: Michael Orrison is a Professor of Mathematics at Harvey Mudd College. He received his A.B. from Wabash College in 1995, and his Ph.D. from Dartmouth College in 2001. His teaching interests include linear algebra, abstract algebra, discrete mathematics, and representation theory. His research interests include voting theory and harmonic analysis on finite groups. He particularly enjoys finding, exploring, and describing novel applications of the representation theory of finite groups with the help of his talented and energetic undergraduate research students.
Speaker: Tina Eliassi-Rad, Northeastern University
Date & Time: March 29, 5:30-6:30p ET
Title: What can Complexity Science do for Democracy?
Abstract: We will discuss the following questions. What is democratic backsliding? Is democratic backsliding an indicator of instability in the democratic system? If so, which processes potentially lead to this instability? If we think of democracy as a complex system, how can complexity science help us understand and mitigate democratic backsliding? This talk is based on these two papers: K. Wiesner et al. (2018) in European Journal of Physics (https://doi.org/10.1088/1361-6404/aaeb4d) and T. Eliassi-Rad et al. (2020) in Humanities & Social Sciences Communication (https://www.nature.com/articles/s41599-020-0518-0).
Bio: Tina Eliassi-Rad is a Professor of Computer Science at Northeastern University in Boston, MA. She is also a core faculty member at Northeastern’s Network Science Institute. Prior to joining Northeastern, Tina was an Associate Professor of Computer Science at Rutgers University; and before that she was a Member of Technical Staff and Principal Investigator at Lawrence Livermore National Laboratory. Tina earned her Ph.D. in Computer Sciences (with a minor in Mathematical Statistics) at the University of Wisconsin-Madison. Her research is at the intersection data mining, machine learning, and network science. She has over 100 peer-reviewed publications (including a few best paper and best paper runner-up awardees); and has given over 200 invited talks and 14 tutorials. Tina’s work has been applied to personalized search on the World-Wide Web, statistical indices of large-scale scientific simulation data, fraud detection, mobile ad targeting, cyber situational awareness, and ethics in machine learning. Her algorithms have been incorporated into systems used by the government and industry (e.g., IBM System G Graph Analytics) as well as open-source software (e.g., Stanford Network Analysis Project). In 2017, Tina served as the program co-chair for the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (a.k.a. KDD, which is the premier conference on data mining) and as the program co-chair for the International Conference on Network Science (a.k.a. NetSci, which is the premier conference on network science). In 2020, she served as the program co-chair for the International Conference on Computational Social Science (a.k.a. IC2S2, which is the premier conference on computational social science). Tina received an Outstanding Mentor Award from the Office of Science at the US Department of Energy in 2010; became a Fellow of the ISI Foundation in Turin Italy in 2019; and was named one of the 100 Brilliant Women in AI Ethics for 2021.
Speaker: Kate Starbird, University of Washington
Date & Time: Monday, March 8, 5:30-6:30p ET
Place: Zoom meeting — contact seminar organizers for details
Title: Online Misinformation during Crisis Events: The “Perfect Storm” of Covid-19 and Election2020
Abstract: The past year has been a difficult one. A pandemic has taken millions of lives and disrupted “normal” routines across the globe. In the United States, we have experienced an unprecedented political situation with a sitting President refusing to concede after losing an election. Each of the events has been accompanied by uncertainty and anxiety, as well as massive amounts of false and misleading information. In this talk, I will explore some of the mechanics of online misinformation, explaining why we are particularly vulnerable right now — due in part to the nature of these crises, and in part to the current structure of our information systems. Using examples from both Covid19 and Election2020, I will explain how we are living through a “perfect storm” for both misinformation and disinformation. And I will describe how disinformation, in particular, can be an existential threat to democratic societies. After laying out the problems, I aim to end on a more hopeful note, with a call to action for researchers and industry professionals to help “chip away” at this critical societal issue.
Bio: Kate Starbird is an Associate Professor at the Department of Human Centered Design & Engineering (HCDE) at the University of Washington (UW). Kate’s research sits in the emerging field of crisis informatics—the study of the how social media and other communication technologies are used during crisis events. Currently, her work focuses on the production and spread of online rumors, misinformation, and disinformation in the crisis context. Starbird is a co-founder of the UW Center for an Informed Public.
Fall 2021
Speaker: Gregory Herschlag, Duke University
Recording: View Gregory Herschlag Lecture Recording
Date & Time: Monday, December 13, 2021, 5:30-6:30pm ET
Place: Zoom meeting — contact seminar organizers for details
Title: Quantifying Gerrymandering: Advances in Sampling Graph Partitions from Policy-Driven Measures
Abstract: Gerrymandering is the process of manipulating political districts either to amplify the power of a political group or suppress the representation of certain demographic groups. Although we have seen increasingly precise and effective gerrymanders, a number of mathematicians, political scientists, and lawyers are developing effective methodologies at uncovering and understanding the effects of gerrymandered districts.
The basic idea behind these methods is to compare a given set of districts to a large collection of neutrally drawn plans. The process relies on three distinct components: First, we determine rules for compliant redistricting plans along with codifying preferences between these plans; next, we sample the space of compliant redistricting plans (according to our preferences) and generate a large collection of non-partisan alternatives; finally, we compare the collection of plans to a particular plan of interest. The first step, though largely a legal question of compliance, provides interesting grounds for mathematical translation between policies and probability measures; the second and third points create rich problems in the fields of applied mathematics (sampling theory) and data analysis, respectively.
In this talk, I will discuss how our research group at Duke has analyzed gerrymandering. I will discuss the sampling methods we employ and discuss several recent algorithmic advances. I will also mention several open problems and challenges in this field. These sampling methods provide rich grounds both for mathematical exploration and development and also serve as a practical and relevant algorithm that can be employed to establish and maintain fair governance.
Bio: Gregory Herschlag received his Ph.D. in mathematics from UNC Chapel Hill in 2013. Since then, he has been in a research position at Duke University that has spanned both the Departments of Biomedical Engineering and Mathematics. He began working with Jonathan Mattingly on algorithms to quantify gerrymandering in 2016; within this collaboration, Greg has analyzed and quantified gerrymandering in the North Carolina congressional districts, the Wisconsin general assembly, and the North Carolina legislature, and more. This work was incorporated into expert testimony in Common Cause v. Rucho, North Carolina v. Covington, and was featured in an Amicus brief submitted to the Supreme Court during Gill v. Whitford. He has also developed several new algorithms to sample and understand the space of redistricting plans. These algorithms are currently being employed to analyze and audit plans in the 2020 redistricting cycle.
Speaker: Ben Blum-Smith, NYU Center for Data Science
Date & Time: Monday, November 22, 5:30-6:30pm ET, followed by a 15 minute Q&A
Place: Zoom meeting — contact seminar organizers for details
Title: Fair-division approaches to redistricting
Abstract: Prominent efforts to fight partisan gerrymandering in the US have sought the help of a (hopefully) neutral arbiter: they have aimed either to elicit intervention from the courts, or to delegate responsibility for redistricting to a formally nonpartisan body such as an independent commission. In this talk, we discuss mechanisms to allow partisan actors to produce a fair map without the involvement of such a neutral arbiter. Inspired by the field of game theory, and more specifically the study of fair-division procedures, the idea is to use the structured interplay of the parties’ competing interests to produce a fair map. We survey the various mechanisms that have been proposed in this fairly young line of research, propose new mechanisms with novel potentially-desirable features, and analyze them numerically.
Bio: Ben Blum-Smith is Mathematician-in-Residence at the Bridge to Enter Advanced Mathematics, Part-Time Faculty at The New School, and a Visiting Academic at the NYU Center for Data Science (CDS). He received his PhD from the Courant Institute of Mathematical Sciences in 2017. He is a founding organizer of the Math and Democracy Seminar at the CDS. He is always on the lookout for new ways in which the power of mathematics can serve democratic goals. He also conducts research in invariant theory, as well as its applications to data science.
Speaker: Jeanne Clelland, University of Colorado Boulder and Beth Malmskog, Colorado College
Recording: View Jeanne Clelland and Beth Malmskog Lecture Recording
Date & Time: Monday, November 1, 5:30-6:30p, ET
Place: Zoom meeting — contact seminar organizers for details
Title: Colorado in Context: A case study in mathematics and fair redistricting in Colorado
Abstract: How do we measure or identify partisan bias in the boundaries of districts for elected representatives? What outcomes are potentially “fair” for a given region depends intimately on its particular human and political geography. Ensemble analysis is a mathematical/statistical technique for putting potential redistricting maps in context of what can be expected for maps drawn without partisan data. This talk will introduce the basics of ensemble analysis, describe some recent advances in creating representative ensembles and quantifying mixing, and discuss how our research group has applied the technique in Colorado both in an academic framework and as consultants to the 2021 Independent Legislative Redistricting Commission.
Bio: Dr. Jeanne Clelland is a Professor in the Department of Mathematics at University of Colorado Boulder. She received her Ph.D. from Duke University in 1996 and completed a National Science Foundation Postdoctoral Research Fellowship at the Institute for Advanced Study prior to joining the faculty at CU-Boulder in 1998. Her research focuses on differential geometry and applications of geometry to the study of differential equations, and more recently on mathematical topics related to redistricting. Dr. Clelland is the author of the textbook From Frenet to Cartan: The Method of Moving Frames, and she is the 2018 winner of the Burton W. Jones Distinguished Teaching Award from the Rocky Mountain Section of the Mathematical Association of America.
Dr. Beth Malmskog is an assistant professor in the Department of Mathematics and Computer Science at Colorado College. Her research is in number theory, algebraic geometry, and applied discrete mathematics. She began working on mathematical aspects of fair redistricting in 2019. Dr. Malmskog earned her PhD at Colorado State University. She serves on the Board of Directors for the League of Women Voters of Colorado.
Speaker: Thomas Weighill, UNC Greensboro
Recording: View Thomas Weighill Lecture Recording
Date & Time: Monday, Oct. 4, 5:30-6:30p, ET
Place: Zoom meeting — contact seminar organizers for details
Title: The Topology of Redistricting
Abstract: Across the nation, legislatures and commissions are deciding where the Congressional districts in their state will be for the next decade. Even under standard constraints such as contiguity and population balance, they will have exponentially many possible maps to choose from. Recent computational advances have nonetheless made it possible to robustly sample from this vast space of possibilities, exposing the question of what a typical map looks like to data analysis techniques. In this talk I will show how topological data analysis (TDA) can help cut through the complexity and uncover key political features of redistricting in a given state. This is joint work with Moon Duchin and Tom Needham.
Bio: Thomas Weighill is an Assistant Professor at the University of North Carolina at Greensboro. He received his PhD from the University of Tennessee, after which he was a postdoc at the MGGG Redistricting Lab at Tufts University. His research focuses on geometry and topology and their applications to data science, particularly to Census and election data.
Spring 2020
Speaker: Solon Barocas, Microsoft Research and Cornell University
Date & Time: Wednesday, April 29, 5:30-6:30 ET
Place: Zoom meeting — contact seminar organizers for details
Title: What Is a Proxy and Why Is it a Problem?
Abstract: Warnings about so-called ‘proxy variables’ have become ubiquitous in recent policy debates about machine learning’s potential to discriminate illegally. Yet it is far from clear what makes something a proxy and why it poses a problem. In most cases, commentators seem to worry that even when a legally proscribed feature such as race is not provided directly as an input into a machine learning model, discrimination on that basis may persist because non-proscribed features are correlated with — that is, serve as a proxy for — the proscribed feature. Analogizing to redlining, commentators point out that zip codes can easily serve as a stand in for race. Yet, unlike lenders, a machine learning model will not seize on zip codes because the model intends to discriminate on race; it will only do so because zip codes also happen to be predictive of the outcome of interest. So how are we to decide whether a variable is serving as a proxy for race or as a legitimate predictor that just happens to be correlated with race? This question cuts to the core of discrimination law, posing both practical and conceptual challenges for resolving whether any observed disparate impact is justified when a decision relies on variables that exhibit any correlation with class membership. This paper attempts to develop a more principled definition of proxy variables, aiming to bring improved clarity to statistical, legal, and normative reasoning on the issue. It describes the various conditions that might create a proxy problem and explores a wide range of possible responses. In so doing, it reveals that any rigorous discussion of proxy variables requires excavating the causal relationship that different commentators assume to exist between non-proscribed features, proscribed features, and the outcome of interest. Joint with Margarita Boyarskaya and Hanna Wallach.
Bio: Solon Barocas is a Principal Researcher in the New York City lab of Microsoft Research and an Assistant Professor in the Department of Information Science at Cornell University. He is also a Faculty Associate at the Berkman Klein Center for Internet & Society at Harvard University. His research explores ethical and policy issues in artificial intelligence, particularly fairness in machine learning, methods for bringing accountability to automated decision-making, and the privacy implications of inference. He co-founded the annual workshop on Fairness, Accountability, and Transparency in Machine Learning (FAT/ML) and later established the ACM conference on Fairness, Accountability, and Transparency (FAT*). He was previously a Postdoctoral Researcher at Microsoft Research as well as a Postdoctoral Research Associate at the Center for Information Technology Policy at Princeton University. He completed his doctorate at New York University.
Speaker: Joshua Loftus, New York University
Recording: View Joshua Loftus Lecture Recording
Date & Time: Wednesday, February 12, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: Statistical aspects of algorithmic fairness
Abstract: The social impact of technology has recently generated a lot of work in the machine learning research community, but relatively little from statistics. Fundamental issues such as fairness, privacy, and even legal rights such as the right to an “explanation” of an automated decision can not be reduced to properties of a given dataset and learning algorithm, but must account for statistical aspects of the data generating process. In this talk I will survey some recent literature on algorithmic fairness with a focus on methods based on causal inference. One such approach, counterfactual fairness, requires that predictions or decisions be the same both in the actual world and in a counterfactual world where an individual had a different value of a sensitive attribute, such as race or gender. This approach defines fairness in the context of a causal model for the data which usually relies on untestable assumptions. The causal modeling approach is useful for thinking about the implicit assumptions or possible consequences of other definitions, and identifying key points for interventions.
Bio: Joshua R. Loftus joined New York University Stern School of Business as an Assistant Professor of Information, Operations and Management Sciences in September 2017. Professor Loftus studies statistical methodology for machine learning and data science pipelines with a focus on addressing sources and types of error that were previously overlooked. This includes developing methods for inference after model selection that account for selection bias and analyzing fairness of the impact of algorithms on people from a causal perspective. His work has been published in the Annals of Statistics, Biometrika, Advances in Neural Information Processing Systems, and the International Conference on Machine Learning. Before joining NYU Stern, Professor Loftus was a Research Fellow at the Alan Turing Institute, affiliated with the University of Cambridge. Professor Loftus earned a B.S. in Mathematics at Western Michigan University, an M.S. in Mathematics at Rutgers University, and a Ph.D. in Statistics at Stanford University.
Fall 2020
Speaker: Ariel Procaccia, Harvard University
Date & Time: Monday, December 7, 5:30-6:30 ET
Place: Zoom meeting — contact seminar organizers for details
Title: Democracy and the Pursuit of Randomness
Abstract: Sortition is a storied paradigm of democracy built on the idea of choosing representatives through lotteries instead of elections. In recent years this idea has found renewed popularity in the form of citizens’ assemblies, which bring together randomly selected people from all walks of life to discuss key questions and deliver policy recommendations. A principled approach to sortition, however, must resolve the tension between two competing requirements: that the demographic composition of citizens’ assemblies reflect the general population and that every person be given a fair chance (literally) to participate. I will describe our work on designing, analyzing and implementing randomized participant selection algorithms that balance these two requirements. I will also discuss practical challenges in sortition based on experience with the adoption and deployment of our open-source system, Panelot.
Bio: Ariel Procaccia is Gordon McKay Professor of Computer Science at Harvard University. He works on a broad and dynamic set of problems related to AI, algorithms, economics, and society. His distinctions include the Social Choice and Welfare Prize (2020), a Guggenheim Fellowship (2018), the IJCAI Computers and Thought Award (2015), and a Sloan Research Fellowship (2015). To make his research accessible to the public, he has founded the not-for-profit websites Spliddit.org and RoboVote.org, and he contributes regularly to Bloomberg Opinion.
Speaker: Audrey Malagon, Virginia Wesleyan University
Date & Time: Monday, October 26, 5:30-6:30 ET
Place: Zoom meeting — contact seminar organizers for details
Title: Votes of Confidence: Leveraging Mathematics to Ensure Election Integrity
Abstract: Our democracy relies on fair elections in which every vote counts and ensures a peaceful transition of power after the election. Concerns about foreign interference in our elections, unreliable voting technology, disinformation, and last minute changes during the COVID-19 pandemic make this election the most challenging in recent history. In this talk, we’ll discuss how statistical post-election audits play a vital role in ensuring a fair and trustworthy process and other ways that mathematics can help ensure the integrity of our elections.
Bio: Audrey Malagon is Professor of Mathematics at Virginia Wesleyan University and serves as mathematical advisor to Verified Voting, a national non-partisan, nonprofit organization whose mission is to strengthen democracy for all voters by promoting the responsible use of technology in elections. She is a member of the Election Verification Network and active in the Mathematical Association of America. She wrote a guest op-ed for the Virginian Pilot on the importance of mathematical audits in elections and has been quoted in Bloomsberg Businessweek, Stateline, and Slate Future Tense.
Speaker: Momin Malik, MoveOn, Harvard University
Date & Time: Monday, October 5, 5:30-6:30 ET
Place: Zoom meeting — contact seminar organizers for details
Title: A Hierarchy of Limitations in Machine Learning
Abstract: In the immortal words of George E. P. Box (1979), “All models are wrong, but some are useful.” This is an important lesson to recall amidst hopes and claims that the impressive successes of machine learning will extend to wider branches of inquiry, and that its high-dimension and low-assumption models can overcome what previously seemed to be insurmountable barriers. In this talk, I review the fundamental limitations with which all quantitative research into the social world must grapple, and discuss how these limitations manifest today.
I cover sociological and philosophical aspects of the process of quantification and modeling, as well as technical aspects around implications of the bias-variance tradeoff and the effect of dependencies on cross-validation assessments of model performance. I metaphorically structure the set of limitations as a tree, where the root node is the choice to undertake systematic inquiry, the leaf nodes are specific methodological approaches, and each branch (qualitative/quantitative, explanatory/predictive, etc.) represents tradeoffs whose limitations percolate downwards.
This talk will serve as a useful overview about modeling limitations and critiques, as well as possible fixes, for researchers in and practitioners of data science, statistics, and machine learning. It will also be useful as a primer for qualitative and theoretical social scientists on what are solid grounds on which to accept or reject applications of techniques from these areas, as well as where there are promising areas for developing new mixed methods approaches.
Bio: Momin M. Malik is the Data Science Postdoctoral Fellow at the Berkman Klein Center for Internet & Society at Harvard University (on leave at MoveOn). He holds an undergraduate degree in history of science from Harvard, a master’s from the Oxford Internet Institute, and a master’s in Machine Learning and a PhD in Societal Computing from the School of Computer Science, Carnegie Mellon University, where his dissertation measured how much social media platform effects, demographic biases, and reliance on mobile phone sensor data can threaten generalizability of findings in computational social science. His current work bridges machine learning and science studies to understand the sources of both success and failures in machine learning.
Spring 2019
Speaker: Justin Solomon
Date & Time: Wednesday May 15, 5:30-6:30 pm
Place: 60 5th Avenue, Room 150
Title: Counterexamples in Political Redistricting
Abstract: “Efforts to counteract gerrymandering have increased enthusiasm for computational techniques that can design and evaluate voting districts. While algorithms hold the potential to enumerate many ways to district a state and to quantify measures of fairness, partisanship, and geometric quality, careful analysis is needed before we can place trust in software as an unbiased and effective arbiter in redistricting cases. In this talk, I will highlight recent progress in computational aspects of redistricting in parallel with considerations from computational complexity, random sampling, and noisy data processing that should be taken into account as we propose algorithmic options for redistricting. In particular, we will study subtle challenges that arise in methods for measuring district compactness and for gathering aggregate statistics about the “space” of districting plans, as well as potential means of resolving these issues. Particular focus will be put on open problems in need of mathematical, statistical, and algorithmic consideration.
Joint work with R. Barnes, D. DeFord, M. Duchin, H. Lavenant, L. Najt, and Z. Schutzmann.”
Bio: Justin Solomon is an assistant professor of Electrical Engineering and Computer Science at MIT. He leads the Geometric Data Processing Group in the Computer Science and Artificial Intelligence Laboratory and is a member of the MGGG Redistricting Lab.
Speaker: Paul Edelman
Date & Time: Wednesday April 17, 5:30-6:30 pm
Place: 60 5th Avenue, Room 150
Title: Political Hypotheses and Mathematical Conclusions
Abstract: “When modeling or analyzing democratic processes, mathematicians may find themselves in unfamiliar territory: politics. How we proceed mathematically may depend heavily on our conception of representative democracy and theory of government. I will give a number of illustrations to show how contestable political principles lead to differing mathematical analyses. Our mathematical conclusions are inherently governed by our political hypotheses.”
Bio: Paul H Edelman received his PhD in mathematics under the direction of Richard Stanley at MIT in 1980. Since 2000 he has been Professor of Mathematics and Law at Vanderbilt University where he teaches both in the Law School and the Mathematics Department.
Speaker: Mira Bernstein
Date & Time: Wednesday February 27, 5:30-6:30 pm
Place: 60 5th Avenue, Room 150
Title: Statistical tools for fighting gerrymandering
Abstract: “Gerrymandering is the practice of drawing boundaries of electoral districts in a way that unfairly benefits or hurts a particular group of voters. Common targets of gerrymandering include supporters of a political party (partisan gerrymandering) or members of a racial minority (racial gerrymandering). In the US, these two types of gerrymandering have very different legal status, so the mathematical tools required to combat them are completely different as well. In this talk, I will describe statistical approaches to fighting both types of gerrymandering. In the case of partisan gerrymandering, the main difficulty lies in articulating a quantitative standard of partisan fairness and finding ways to measure deviations from this standard. In contrast, for racial gerrymandering, the legal standard is relatively clear; the challenge is to show that race is a relevant variable at all. Racial gerrymandering can only occur if voters of different races tend to vote differently, which is extremely difficult to prove when we have no way of knowing how any individual voted. I will describe existing statistical tools for detecting racially-polarized voting and conclude with my own work on increasing the power of these techniques by combining data from multiple elections.”
Bio: Mira Bernstein is a founding member of the MGGG Redistricting Lab at Tufts. She received her PhD in pure mathematics from Harvard in 1999, but since 2008 her work has focused on using mathematics to solve social problems — from exploring the effects of extending health insurance to low-income populations to combatting slavery and forced labor throughout the world. Mira is also very active in mathematics education. She loves getting her students to see that mathematics, far from being scary and boring, is powerful, fascinating, and highly relevant to their lives.
Fall 2019
Speaker: Kristian Lum, Human Rights Data Analysis Group
Date & Time: Wednesday, December 4, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: Fairness, Accountability, and Transparency: Lessons from predictive models in criminal justice
Abstract: The related topics of fairness, accountability, and transparency in predictive modeling have seen increased attention over the last several years. One application area where these topics are particularly important is criminal justice. In this talk, I will give an overview of my work in this area— spanning a critical look at predictive policing algorithms to the role of police discretion in pre-trial risk assessment models to a look behind the scenes at how risk assessment models are created in practice. Through these examples, I hope to demonstrate the importance of each of these concepts in predictive modeling in general and in the criminal justice system in particular.
Bio: Kristian Lum is the Lead Statistician at the Human Rights Data Analysis Group (HRDAG), where she leads the HRDAG project on criminal justice in the United States. Previously, Kristian worked as a research assistant professor in the Virginia Bioinformatics Institute at Virginia Tech and as a data scientist at DataPad, a small technology start-up. Kristian’s research primarily focuses on examining the uses of machine learning in the criminal justice system and has concretely demonstrated the potential for machine learning-based predictive policing models to reinforce and, in some cases, amplify historical racial biases in law enforcement. She has also applied a diverse set of methodologies to better understand the criminal justice system: causal inference methods to explore the causal impact of setting bail on the likelihood of pleading or being found guilty; and agent-based modeling methods derived from epidemiology to study the disease-like spread of incarceration through a social influence network. Additionally, Kristian’s work encompasses the development of new statistical methods that explicitly incorporate fairness considerations and advancing HRDAG’s core statistical methodology—record-linkage and capture-recapture methods for estimating the number of undocumented conflict casualties. She is the primary author of the dga package, open source software for population estimation for the R computing environment. Kristian received an MS and PhD from the Department of Statistical Science at Duke University and a BA in Mathematics and Statistics from Rice University.
Speaker: Andrew Gelman, Columbia University
Date & Time: Wednesday, October 30, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: Is Statistics Good for Democracy?
Abstract: This talk will be some mix of News You Can Use and Big Idea. You can decide how much you want of each. News You can Use: Latest developments in Bayesian workflow, MRP, and Stan. Big Idea: Statistical methods can be used to better understand public opinion and political behavior. This should improve democracy by enabling and motivating politicians and government officials to be responsive to voters’ desires. But statistics can also be used to evaluate and develop methods for manipulating the public, and the belief in the efficacy of such manipulations can degrade faith in democracy. Open-source data and methods have the potential to equalize the playing field, giving small groups the ability to compete with well-funded institutions and political parties. But many of these methods are most effective with big data that are owned by major corporations. How to go forward?
Bio: Andrew Gelman’s first work in political science was a critique of an influential, enthusiastic, and mistaken application of game theory to social interactions. His later work with various collaborators includes: estimation of the effects of redistricting plans; understanding why opinion polls vary so much when elections are so predictable; probabilistic forecasting of elections; a critique of an influential, enthusiastic, and mistaken application of mathematics to voting power; a study of geographic and social variation in how rich and poor people vote; and studies of political polarization and opinion change. Relatedly, he has done work on Bayesian methods, survey research, and statistical graphics, workflow, and computation.
Speaker: Rediet Abebe, Harvard and Cornell
Date & Time: Wednesday, October 16, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: Mechanism Design for Social Good
Abstract: Poverty and economic hardship are understood to be highly complex and dynamic phenomena. Yet, assistance programs targeted at alleviating hardship often rely on simpler measures of welfare, such as income or wealth, that fail to capture to full complexity of families’ state. In this talk, we explore how we can incorporate one important dimension – susceptibility to income shocks. We introduce a model that relies on income, wealth, and income shocks. We analyze this model to show that it can vary, at times substantially, from measures of welfare that only use families’ income or wealth. We then study the problem of allocating subsidies in the presence of income shocks and present numerous algorithms that optimize for different objectives and ethical considerations that arise in each setting. We close with a discussion on future directions related to allocating scarce societal resources and the Mechanism Design for Social Good research agenda, which aims to use techniques from algorithm design to improve access to opportunity for historically disadvantaged communities.
Bio: Rediet Abebe is a Junior Fellow at the Harvard Society of Fellows and a computer science Ph.D. candidate at Cornell University. Her research is broadly in the fields of algorithms and AI, with a focus on equity, justice, and social good concerns. As part of this research agenda, she co-founded and co-organizes Mechanism Design for Social Good (MD4SG), a multi-institutional, interdisciplinary research initiative with members across 50 institutions and 15 countries. She also co-founded and co-organizes Black in AI, a non-profit organization tackling diversity and inclusion issues in the field. Abebe holds an M.S. in applied mathematics from Harvard University, an M.A. in mathematics from the University of Cambridge, and a B.A. in mathematics from Harvard College. She was recently named one of 35 Innovators Under 35 by the MIT Technology Review and honored in the 2019 Bloomberg 50 list as a “one to watch.” Her work has been covered by outlets including Forbes, The Boston Globe, and The Washington Post. Her research is deeply influenced by her upbringing in her hometown of Addis Ababa, Ethiopia.
Speaker: Jonathan Hodge, Grand Valley State University
Date & Time: Wednesday, September 25, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: Dudum v. Arntz: A Case Study in the Intersection of Mathematics, Politics, and Law
Abstract: In a 2011 court case, Dudum v. Arntz, the Ninth Circuit Court of Appeals upheld the city of San Francisco’s use of restricted Instant Runoff Voting (IRV)—a version of IRV that allows voters to rank at most three candidates. In this talk, we will explore the mathematical arguments and reasoning that arose in this landmark case. Which types of arguments were persuasive, which were not, and what lessons can be learned about the role of mathematics in litigation involving voting and democracy? As we explore these questions, we will also consider some famous theorems about voting and elections, and see how these theorems impacted the Court’s ruling.
Bio: Dr. Jonathan K. Hodge is a Professor of Mathematics at Grand Valley State University. His research is in voting and social choice theory, and he has mentored 30 students in NSF and NSA-funded undergraduate research projects. Dr. Hodge is a co-author of The Mathematics of Voting and Elections: A Hands-On Approach, published by the American Mathematical Society, with a Russian translation published by the Moscow Center for Continuous Mathematical Education. He is a recipient of the Mathematical Association of America’s George Pólya Award and Western Michigan University’s Alumni Achievement Award. In addition to his research and teaching courses throughout the undergraduate mathematics curriculum, Dr. Hodge has held a variety of administrative roles at GVSU, including Chair of the Department of Mathematics, Director of the School of Communications, and his current position as Chair of the Department of Allied Health Sciences.
Speaker: Dustin Mixon, Ohio State University
Date & Time: Wednesday, September 18, 5:30-6:30
Place: 60 5th Avenue, 7th floor [note: floor access restricted after 6pm]
Title: The Mathematics of Partisan Gerrymandering
Abstract: Every decade, politicians update voting districts to account for population shifts as measured by the U.S. Census. Of course, partisan politicians are inclined to draw maps that favor their own party, resulting in partisan gerrymandering. In this talk, we will explore how tools from mathematics can help to deter this growing threat to democracy.
Bio: Dustin G. Mixon is an assistant professor of mathematics at The Ohio State University. He studies interactions between algebra, geometry, combinatorics and data science. His recent work on the mathematics of gerrymandering has been featured in New Scientist and Forbes, among others.
Spring 2018
Speaker: Wesley Pegden, Carnegie Mellon
Date & Time: Tuesday May 8, 12:00pm
Place: 60 5th Avenue, Room 150
Title: Detecting gerrymandering with mathematical rigor
Abstract: In February of this year, the Pennsylvania Supreme Court found Pennsylvania’s Congressional districting to be an unconstitutional partisan gerrymander. In this talk, I will discuss one of the pieces of evidence which the court used to reach this conclusion. In particular, I will discuss a theorem which allows us to use randomness to detect gerrymandering of Congressional districtings in a statistically rigorous way.
Fall 2018
Speaker: Steven Brams, NYU
Date & Time: Monday November 19, 5:30-6:30pm
Place: 60 5th Ave, Room C10
Title:Is There a Better Way to Elect a President?
Abstract: Properties of approval voting—whereby voters can approve of as many candidates as they like in a multi-candidate election, and the candidate with the most approval wins—are compared with properties of (1) plurality voting, in which voters can vote for only one candidate; (2) ranking systems, such as the Borda count and the Hare system of single transferable vote (also called instant runoff or ranked choice voting); and (3) grading systems that have been proposed by several mathematicians. Approval voting, which is used to elect popes, the UN secretary general, and presidents of several professional societies, is a simpler and more practicable alternative that I argue should be used in presidential and other public elections. Extending approval voting to multi-winner elections, such as to a committee or council, will also be discussed.
Bio: Steven J. Brams is Professor of Politics at New York University and the author, co-author, or co-editor of 18 books and about 300 articles. He holds two patents for fair-division algorithms and is chairman of the advisory board of Fair Outcomes, Inc.
Brams has applied game theory and social-choice theory to voting and elections, bargaining and fairness, international relations, and the Bible, theology, and literature. He is a former president of the Peace Science Society (1990-91) and of the Public Choice Society (2004-2006). He is a Fellow of the American Association for the Advancement of Science (1986), a Guggenheim Fellow (1986-87), and was a Visiting Scholar at the Russell Sage Foundation (1998-99).
Speaker: Zajj Daugherty, City College
Date & Time: Monday November 5, 5:30-6:30pm
Place: 60 5th Ave, Room C10 (note different room)
Title: An algebraic approach to voting theory
Abstract: In voting theory, simple questions can lead to complex and sometimes paradoxical results. Recently, we have been able to use tools from modern algebra to address long-standing arguments over voting and tallying methods that date back to the days of Jean-Charles de Borda and Nicolas de Condorcet. In this talk, we’ll explore how to frame voting methodology in terms of combinatorics and representations of finite groups.
Bio: Zajj Daugherty is an Assistant Professor of Mathematics at the City College of New York. She received her PhD from the University of Wisconsin Madison in 2010, and was a postdoc at Dartmouth College, the Institute for Computational and Experimental Research in Mathematics, and the University of Melbourne. Her research is primarily in combinatorial representation theory, with applications in statistical mechanics. But she got her start in the field via voting theory as an undergraduate researcher at Harvey Mudd College, and has enjoyed revisiting the topic via a recent surge in interest in the topic in her community.
Speaker: Shira Mitchell, NYC Mayor’s Office
Date & Time: Wednesday October 31, 5:30-6:30 pm
Place: 60 5th Avenue, Room 150
Title: Prediction-based decisions and fairness: choices, assumptions, and definitions
Abstract: A recent flurry of research activity attempts to define “fairness” quantitatively, especially in decisions based on statistical and machine learning (ML) predictions. The field’s rapid growth has led to wildly inconsistent terminology and notation, presenting a serious challenge for comparing definitions. Our work attempts to bring much-needed order. First, we explicate the various choices and assumptions made—often implicitly—in developing a prediction-based decision system. We then use these to motivate concerns about fairness, and present definitions of fairness from the statistics and ML literature in a notationally consistent catalogue. In doing so, we offer designers of prediction-based decision systems a way to think through choices, assumptions, and fairness considerations.
Bio: Shira Mitchell is a statistician and slow thinker. After her PhD at Harvard and postdoc at Columbia, she spent two years at Mathematica Policy Research working on small area estimation and causal inference for federal agencies (mostly Medicare and Medicaid). Now she is at the NYC Mayor’s Office of Data Analytics (MODA), working with city agencies to both deploy and critique data-driven policy.